ИНФОЛОГИЧЕСКОЕ МОДЕЛИРОВАНИЕ
Инфологическая модель создается по результатам проведения исследований предметной области.
Инфологическая модель представляет собой описание будущей базы данных, представленное с помощью естественного языка, формул, графиков, диаграмм, таблиц и других средств, понятных как разработчикам БД, так и обычным пользователям.
Назначение такой модели состоит в адекватном описании процессов, информационных потоков, функций системы с помощью общедоступного и понятного языка, что делает возможным привлечение экспертов предметной области, консультантов, пользователей для обсуждения модели и внесения исправлений. В данном случае под созданием инфологической модели будем понимать именно ее создание для БД. В общем случае, инфологическая модель может создаваться для любой проектируемой системы и представляет ее описание (в общем случае в произвольной форме).
Создание инфологической модели является естественным продолжением исследований предметной области, но в отличие от него является представлением БД с точки зрения проектировщика (разработчика). Наглядность представления такой модели позволяет экспертам предметной области оценить ее точность и внести исправления. От правильности модели зависит успех дальнейшей разработки.
Инфологическую модель можно представить в виде словесного описания, однако наиболее наглядным является использование специальных графических нотаций, разработанных для проведения подобного рода моделирования.
Важно отметить, что создаваемая на этом этапе модель полностью не зависит от физической реализации будущей системы. В случае с БД это означает, что совершенно не важно где физически будут храниться данные: на бумаге, в памяти компьютера и кто или что эти данные будет обрабатывать. В этом случае, когда структуры данных не зависят от их физической реализации, а моделируются исходя из их смыслового назначения, моделирование называется семантическим.
Существует несколько способов описания инфологической модели, однако, в настоящее время одним из наиболее широко распространенных подходов, применяемых при инфологическом моделировании, является подход, основанный на применении диаграмм «сущность-связь» (ER – Entity Relationship). При рассмотрении последующих примеров будем использовать одну из самых распространенных в рамках ER моделей нотацию IDEF1X. Данный стандарт был разработан в 1993 г. Национальным институтом стандартизации и технологий и является федеральным стандартом обработки информации (США), описывающим семантику и синтаксис языка, правила и технологии для разработки логической модели данных.
Для построения инфологической модели важно знать элементы этой модели. Базовыми элементами модели сущность-связь являются сущности.
Сущность по форме представляет собой только некоторое реального описание объекта, точнее набор описаний его значимых признаков-атрибутов. Конкретный набор значений атрибутов объекта будет называться экземпляром сущности. 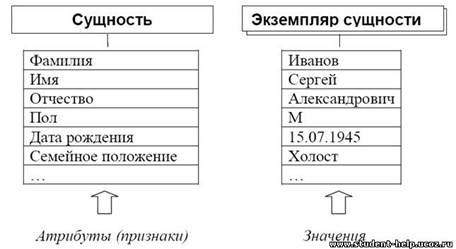
Рис. 1. Сущность и экземпляр сущности
Как видно из рис. 1, понятие «сущность» – означает форму информации, ее смысл. Понятие «элемент сущности» – отражает содержание.
Так, без наличия описания информации (т.е. сущности) будет трудно понять содержание следующей информации
| ИВАНОВ |
| СЕРГЕЙ |
| АЛЕКСАНДРОВИЧ |
| М |
| 15.07.1945 |
| ХОЛОСТ |
| . |
Это может быть как описанием объекта «сотрудник предприятия», так и описанием объекта «покупатель», или чем-то иным.
Поэтому, процесс выделения сущностей из автоматизируемой предметной области и их описание является ключевым для создания любых структур данных.
В качестве сущности может быть выбран не только объект, но и явление, процесс, трансформация, действие.
Если автоматизируется какой-либо процесс, то необходимо указать свойства этого процесса, объекты участвующие в этом процессе.
Пример. При автоматизации процесса покупки товаров (сущность «Покупка товаров») необходимо указать:
· какой товар необходимо купить (сущность «Товар»);
· у кого его необходимо купить (сущность «Продавец»);
· другие признаки операции покупка товара, такие как «количество», «цена», «сумма» и пр.
Отсюда следует, что сущности, выделенные из предметной области могут быть связанными между собой. Одна сущность может ссылаться на другую и даже быть признаком другой сущности более высокого уровня (так, сущность «сотрудник» может быть элементом или необходимым атрибутом сущности «организация»).
Понятие «связь» между сущностями представляет собой наличие какой-либо зависимости, ассоциации между сущностями – т.е. наличие информационной или логической связи между объектами автоматизируемой предметной области.
Существует множество видов сущностей и связей между ними.
Рассмотрим понятие их более подробно:
Итак, сущность – это реальный или воображаемый объект реального мира, имеющий существенное значение для рассматриваемой предметной области, информацию о котором необходимо хранить в БД. В некоторых случаях сущностью может являться событие, процесс или явление, имеющие место в реальном мире.
Фактически каждая сущность представляет собой множество подобных индивидуальных объектов, именуемых экземплярами. Имя сущности дается по имени ее экземпляра. Каждый экземпляр сущности индивидуален и должен отличаться от других экземпляров. Это отличие выражается в наличии у каждого экземпляра сущности уникальных свойств, называемых атрибутами.
Примерами сущностей могут быть Товар, Клиент, Покупатель. Наименование товара «Кирпич» является экземпляром сущности товар. Один и тот же объект реального мира может являться экземпляром нескольких сущностей. Так Иванов И.И. может быть как клиентом, так и покупателем, а также являться сотрудником фирмы.
Согласно нотации IDEF1X сущности изображаются в виде прямоугольников, как это показано на рис. 2.

Рис. 2. Пример изображения сущностей на ER диаграмме
Процесс выделения сущностей из автоматизируемой предметной области и их описание является ключевым для создания любых структур данных.
В качестве сущности может быть выбран не только объект, но и явление, процесс, действие.
Если автоматизируется какой-либо процесс, то необходимо указать свойства этого процесса, объекты участвующие в нем.
Например, при автоматизации процесса покупки товаров необходимо указать:
· какой товар необходимо купить (сущность «Товар»);
· у кого его необходимо купить (сущность «Продавец»);
· другие признаки: «Количество», «Цена», «Сумма» и пр. (сущность «Покупка товаров»).
Отсюда следует, что сущности, выделенные из предметной области могут быть связанными между собой. Одна сущность может ссылаться на другую и даже быть признаком другой сущности более высокого уровня (так, сущности «Товар» и «Продавец» могут быть элементами или необходимыми атрибутами сущности «Покупка товаров», сущность «Сотрудник» – элементом или необходимым атрибутом сущности «Организация»).
Понятие связь между сущностями представляет собой наличие какой-либо зависимости, ассоциации между сущностями – т.е. наличие информационной или логической связи между объектами автоматизируемой предметной области.
Ключевым моментом в методологии IDEF1X является взаимосвязь или отношения в которых находятся сущности. Форма взаимодействия одной сущности с другими является важной ее характеристикой. Различают два основных вида взаимодействия. Сущность является независимой если каждый ее экземпляр может быть однозначно идентифицирован без установления связей с другой сущностью. Сущность является зависимой (дочерней), если уникальная идентификация ее экземпляров возможна только путем установления связи с другой сущностью.
Например, сущности «Отдел» и «Сотрудник» являются независимыми, если предположить, что сотрудник может работать в организации, не числясь ни в одном отделе. Примером зависимой сущности может являться сущность «Заказ» в паре сущностей «Клиент»-«Заказ». Информация о заказе не имеет смысла без информации о клиенте его разместившем.
Согласно нотации IDEF1X независимые сущности изображаются в виде обычных прямоугольников, зависимые – в виде прямоугольников со скругленными углами, как это показано на рис.38. При нанесении на ER диаграмму сущности, необходимо руководствоваться следующими требованиями:
· сущность должна иметь наименование с четким смысловым значением и именоваться существительным в единственном числе.
· сущность должна обладать уникальным в пределах модели именем, имеющим четкое смысловое значение, выраженное в виде существительного в единственном числе, которое записывается над прямоугольником;
· именование сущности обычно производится по имени ее экземпляра, а единственное число облегчает в дальнейшем чтение модели.
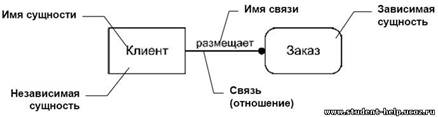
Рис. …. Пример изображения связей между сущностями в нотации IDEF1X
Сущность «Заказ» на рис.3 изображена в виде прямоугольника со скругленными углами, т.к. является зависимой от клиента. Зависимость эта обусловлена тем, что экземпляр сущности «Заказ» не может существовать, если не указан клиент, его разместивший. «Заказ» в свою очередь, может являться независимой по отношению к сущности «Состав заказа», содержащей информацию о наименованиях, количестве и стоимости заказанных товаров или услуг. В этом случае сущности «Заказ» и «Состав заказа» являются зависимыми и изображаются в виде прямоугольников со скругленными углами, сущность «Клиент», является независимой и изображается в виде обычного прямоугольника.
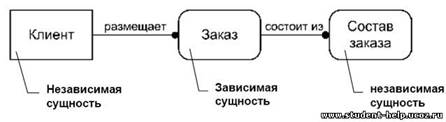
Рис. …. Изображение зависимых сущностей «Заказ» и «Состав заказа»
Таким образом, если сущность имеет несколько отношений с другими сущностями и при этом хотя бы в одном случае является зависимой, она изображается как зависимая.
Атрибут сущности – это именованная характеристика, являющаяся некоторым свойством сущности, значимым для рассматриваемой предметной области. Наименование атрибута должно быть выражено существительным в единственном числе и быть уникальным в пределах БД.
Примерами атрибутов могут являться «Номер клиента», «Имя клиента», «Номер заказа», «Дата заказа» и др. На ER диаграмме атрибуты помещаются внутри прямоугольника. В этом случае название сущности размещается за пределами прямоугольника. Ключевые атрибуты помещаются в списке атрибутов первыми и отделяются от неключевых горизонтальной линией (рис….).
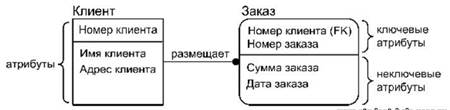
Рис. …. Отображение атрибутов сущности на ER диаграмме
На этапе инфологического моделирования мы скорее имеем дело с признаками сущности.
Признак – это обобщенная характеристика сущности, позволяющая описать ее свойства не вдаваясь в подробности.
На этапе инфологического моделирования признаки выступают в роли атрибутов. На этом этапе от разработчика не требуется проводить глубокий анализ сущности с целью выяснения всех ее атрибутов и их характеристик. Достаточно просто установить, что сущность обладает определенным набором признаков, которые необходимо выделить. В дальнейшем, при создании даталогической модели, признаки трансформируются в атрибуты, или наборы атрибутов, в зависимости от их сложности.
Ключ сущности – это атрибут или набор атрибутов, значения которых однозначно идентифицируют экземпляр сущности.
При инфологическом моделировании необходимо говорить о ключевых признаках. Таким образом, для идентификации сущности необходимо выделить ключевой признак.
Ключ сущности может быть сложным (составным), состоящим из нескольких атрибутов или признаков. При этом комбинация значений атрибутов, входящих в ключ, должна быть уникальной в пределах сущности. Выбор первичного ключа является очень важной и зачастую непростой задачей, от решения которой может зависеть эффективность будущей БД. Сложность выбора обусловлена тем, что, во-первых, значение ключевого атрибута должно быть уникальным в пределах сущности, а во-вторых, в одной сущности может существовать несколько атрибутов или их наборов, подходящих на роль ключа сущности. Такие атрибуты (наборы атрибутов) называются потенциальными ключами (кандидатами). Один атрибут или набор атрибутов из числа кандидатов должен быть выбран в качестве первичного ключа. При этом он должен удовлетворять следующим требованиям:
· уникальности – два экземпляра сущности не должны иметь одинаковых значений возможного ключа;
· компактности – составной ключ не должен содержать ни одного атрибута, удаление которого не приводило бы к утрате уникальности;
· значимости – атрибут ключа не должен быть пустым;
· постоянства – значение атрибутов ключа не должно меняться в течение всего времени существования экземпляра сущности.
Если существует несколько кандидатов на роль первичного ключа, предпочтение следует отдавать более простому (содержащему меньшее количество атрибутов) ключу. Ключи, входящие в список кандидатов, но не ставшие первичными называются альтернативными ключами. На ER диаграмме такие атрибуты помечаются символами (AK) после имени атрибута.
На рис. изображена сущность «Контрагент», в качестве потенциальных ключей которой можно выделить:
1. «Код контрагента» (АК1.1);
2. «Наименование контрагента» (АК2.1) + «Телефон» (АК2.2);
3. «Город контрагента» (АК3.1)+ «Адрес контрагента» (АК3.2).

Рис. …. Альтернативные ключи сущности «Контрагент»
Если учесть очень маленькую вероятность существования двух контрагентов с одинаковыми наименованиями и телефонами или расположенных в городах с одинаковыми названиями и по одинаковым адресам, то второй и третий варианты подойдут на роль первичного ключа, однако, существует еще первый вариант, который проще по составу чем второй и третий – «Код контрагента». Это «синтетический» атрибут, т.к. не имеет прямого отношения к сущности «Контрагент», ведь не существует единого классификатора всех контрагентов, в котором каждому из них соответствует свой уникальный номер. «Код контрагента» в данном случае – это номер, присвоенный ему в пределах данной организации.
С точки зрения теории баз данных использование атрибута «Код контрагента» в качестве ключевого неправильно, так как он не в состоянии обеспечить уникальности экземпляров сущности, ведь можно ввести дважды данные об одном и том же контрагенте, присвоив им при этом разные коды. При этом сущность окажется не только избыточной, но также может произойти нарушение целостности информации в БД вследствие использования в связанных с контрагентом сущностях информации об одном и том же контрагенте, ссылаясь на него при этом по разным номерам.
Иллюстрация такого случая приведена на рис.3.7. Видно, что всего было оформлено 3 заказа Контрагентом 1. Но, так как в списке контрагентов ему соответствуют коды 1 и 3, то в одном случае заказ был оформлен Контрагентом с кодом 1, а во втором – с кодом 3. С точки зрения СУБД Контрагент 1 с кодом 1 и Контрагент 1 с кодом 3 являются разными экземплярами. Если не исправить данное положение, то со временем это приведет к серьезным трудностям в обработке информации БД, связанной с получением итоговых сведений.
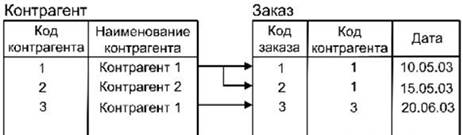
Рис. 3.7 Пример нарушения целостности информации базы данных
Тем не менее, на практике, в силу особенностей реализации технологий реляционных СУБД, используется именно такой подход, при котором очень часто в качестве первичного ключа сущности используется именно суррогатный ключ (код или номер), а контроль целостности информации и избыточность остаются либо «на совести» пользователя, от которого требуется повышенное внимание при добавлении информации в БД, либо «на совести» программиста, реализующего различные блокировки.
Следующим важным понятием в методе «сущность-связь» является понятие отношения между сущностями.
Отношение (связь) – это некоторая ассоциация (логическое соотношение) между двумя сущностями, предполагающая зависимость между атрибутами этих сущностей.
Связи позволяют по одной сущности находить другие сущности, связанные с ней. Название связи обычно представляется глаголом или глагольной фразой (отглагольным существительным), которая выражает некоторое ограничение или бизнес-правило и облегчает чтение диаграммы. Изображенная на рис. связь позволяет определить какие именно заказы разместил клиент и какой именно сотрудник оформил заказ. Глагольные фразы облегчают понимание смысла связи и могут быть созданы как для прямого, так и для обратного чтения связи. Так, в примере, представленном на рис. связь между сущностями «Клиент» и «Заказ» может быть прочитана следующим образом: Клиент размещает Заказ, Заказ размещается Клиентом. Обычно достаточно создания одной глагольной фразы для чтения связи в направлении от независимой сущности к зависимой, исключением являются связи типа многие-ко-многим, при которых для лучшего понимания типа связи желательно создание двух глагольных фраз.
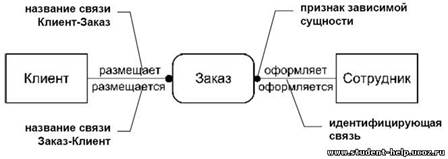
Пример изображения связи на ER диаграмме
На этапе инфологического моделирования используют идентифицирующие и неидентифицирующие связи. Выше было сказано о том, что существуют зависимые и независимые сущности. Тип связи между двумя сущностями определяет какая из них является зависимой (дочерней), а какая – независимой (родительской).
Идентифицирующая связь устанавливается между родительской и дочерней сущностями и означает, что каждому экземпляру дочерней сущности должен соответствовать хотя бы один экземпляр родительской. При этом дочерняя сущность не может существовать «вне рамок» родительской. На ER диаграммах идентифицирующая связь показывается в виде сплошной линии. Точка на линии ставится со стороны дочерней сущности (рис.43). Неидентифицирующая связь устанавливается между двумя независимыми сущностями и означает, что каждый экземпляр дочерней сущности может быть идентифицирован без использования экземпляра родительской сущности. На ER диаграммах неидентифицирующая связь показывается в виде пунктирной линии (рис.44).
Пусть даны две сущности «Материал» и «Единица измерения». Если предположить, что при учете материалов в БД можно не указывать единицу измерения данного материала, то сущности «Материал» и «Единица измерения» являются независимыми, а связь между ними – неидентифицирующей (рис.44).
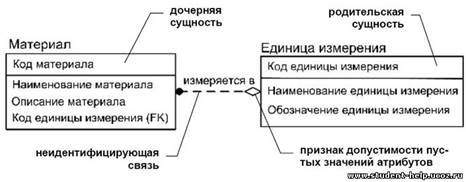
Пример неидентифицирующей связи между сущностями
Связь между сущностями обеспечивается за счет миграции атрибутов родительской сущности в дочернюю.
Миграция – перенос атрибутов одной сущности в другую для установления связи между ними.
Мигрировавший атрибут называется внешним ключом и помечается на ER диаграмме символами (FK) (Foreign Key). Мигрировавший атрибут или группа атрибутов могут быть помещены в состав первичного ключа сущности или в состав неключевых атрибутов в зависимости от типа связи между сущностями. При этом действуют следующие правила:
· если сущности связаны идентифицирующей связью, то все ключевые атрибуты родительской сущности мигрируют в состав первичного ключа дочерней сущности (рис.40);
· если сущности связаны неидентифицирующей связью, то все ключевые атрибуты родительской сущности мигрируют в состав неключевых атрибутов дочерней сущности (рис.44).
При этом возможны два варианта отношений:
Допускаются пустые значения внешних ключей в дочерней сущности (знак ромба на неидентифицирующей связи со стороны независимой сущности).
Пустые значения внешних ключей в дочерней сущности не допускаются (отсутствие знака ромба со стороны независимой сущности).
Каждая связь, независимо от того, является ли она идентифицирующей или нет обладает мощностью.
Мощность связи (cardinality) – характеристика связи между сущностями, предназначенная для обозначения отношения числа экземпляров родительской сущности к числу экземпляров дочерней.
Существует четыре различных типа мощности (рис.45):
1. Одному экземпляру родительской сущности соответствуют 0, 1 или много экземпляров дочерней сущности. Не помечается дополнительным значком на диаграмме.
2. Одному экземпляру родительской сущности соответствуют 1 или много экземпляров дочерней сущности (исключено нулевое значение). На диаграмме помечается значком P.
3. Одному экземпляру родительской сущности соответствуют 0 или 1 экземпляр дочерней сущности (исключены множественные значения). На диаграмме помечается значком Z.
4. Одному экземпляру родительской сущности соответствует заранее заданное число экземпляров дочерней сущности. На диаграмме помечается цифрой.
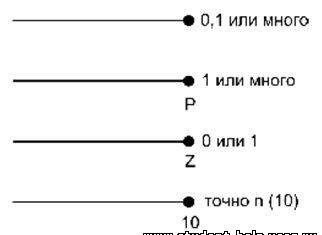
Обозначение мощности в нотации IDEF1X
Существует еще одна, не вошедшая в приведенный выше перечень, мощность связи – многие-ко-многим. Такая связь возможна только на логическом уровне представления модели и означает, что каждому экземпляру родительской сущности может соответствовать несколько экземпляров дочерней, а каждому экземпляру дочерней – несколько экземпляров родительской.
В этом случае понятия «родительская» и «дочерняя» применимы к обоим связываемым сущностям. На диаграмме такая связь обозначается сплошной линией с двумя точками на концах. Обе сущности, участвующие в связи обозначаются как независимые. Пример такой связи приведен на рис.46. В данном случае, в отгрузку могут быть включены несколько товаров, в то же время один товар может участвовать в нескольких отгрузках.
Особой разновидностью связей является категориальная связь, используемая для описания структур, в которых сущность является типом (категорией) другой сущности. При этом родительская сущность (родовой предок) содержит общие свойства, присущие дочерним (категориальным) сущностям. Категориальную связь, называемую иногда иерархией наследования создают тогда, когда несколько сущностей имеют общие по смыслу атрибуты, либо когда сущности имеют общие по смыслу связи, либо когда это диктуется бизнес-правилами. Для каждой категории можно указать дискриминатор – атрибут родового предка, который показывает, как отличить одну категориальную сущность от другой.
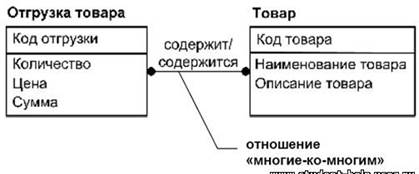
Пример связи «многие-ко-многим»
В качестве примера рассмотрим следующий случай: допустим, известно, что при оформлении операций, связанных с перемещением товарно-материальных ценностей в организации используется два вида накладных: приходная и расходная. В данном случае сущность «Накладная» является родительской, так как объединяет общие для обеих сущностей атрибуты, а сущности «Приходная» и «Расходная» содержат информацию об особенностях накладных каждого вида. Дискриминатором в данном случае будет вид накладной (рис.47).
Категориальные связи делятся на два типа – полные и неполные. Если экземпляру родового предка соответствует экземпляр в каком-либо потомке, то связь является полной, на ER диаграмме изображается с помощью дискриминатора (рис.47). Если категория еще не выстроена полностью и в родовом предке есть экземпляры, для которых нет соответствующих экземпляров в потомках, категория является неполной, на ER диаграмме изображается с помощью дискриминатора (рис.47). Возможны иерархии наследования, в которых присутствуют и полные и неполные категории. При этом сущности, в одном случае являющиеся потомками, могут одновременно являться предками по отношению к другим связям.
В примере, изображенном на рис.47 первая категориальная связь (вид накладной) является полной, т.к. существует только два вида накладных: приходная и расходная. Тип расходной накладной является неполной категориальной связью, т.к. предполагается, что сюда включены еще не все сущности данной категории (например отгрузка материалов на сторону или списание материалов). Отсутствие сущности на диаграмме может быть обусловлено тем, что еще не выявлено ее существование в рамках данной модели, не установлен ее тип или ее существование внутри модели нежелательно.
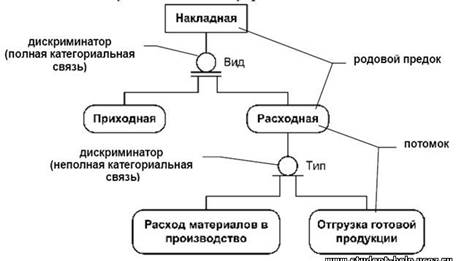
Пример полной и неполной категориальной связи
Код атрибута в пределах одной сущности должен быть уникален
Широкое распространение реляционных СУБД и их использование в самых разнообразных приложениях показывает, что реляционная модель данных достаточна для моделирования предметных областей. Однако проектирование реляционной базы данных в терминах отношений на основе кратко рассмотренного нами механизма нормализации часто представляет собой очень сложный и неудобный для проектировщика процесс.
Потребности проектировщиков баз данных в более удобных и мощных средствах моделирования предметной области вызвали к жизни направление семантических моделей данных. При том, что любая развитая семантическая модель данных, как и реляционная модель, включает структурную, манипуляционную и целостную части, главным назначением семантических моделей является обеспечение возможности выражения семантики данных.
Прежде, чем мы коротко рассмотрим особенности одной из распространенных семантических моделей, остановимся на их возможных применениях.
Наиболее часто на практике семантическое моделирование используется на первой стадии проектирования базы данных. При этом в терминах семантической модели производится концептуальная схема базы данных, которая затем вручную преобразуется к реляционной (или какой-либо другой) схеме. Этот процесс выполняется под управлением методик, в которых достаточно четко оговорены все этапы такого преобразования.
Менее часто реализуется автоматизированная компиляция концептуальной схемы в реляционную. При этом известны два подхода: на основе явного представления концептуальной схемы как исходной информации для компилятора и построения интегрированных систем проектирования с автоматизированным созданием концептуальной схемы на основе интервью с экспертами предметной области. И в том, и в другом случае в результате производится реляционная схема базы данных в третьей нормальной форме (более точно следовало бы сказать, что автору неизвестны системы, обеспечивающие более высокий уровень нормализации).
4.5.1. Диаграммное представление
На использовании разновидностей ER-модели основано большинство современных подходов к проектированию баз данных (главным образом, реляционных). Модель была предложена Ченом (Chen) в 1976 г. Моделирование предметной области базируется на использовании графических диаграмм, включающих небольшое число разнородных компонентов. В связи с наглядностью представления концептуальных схем баз данных ER-модели получили широкое распространение в системах CASE, поддерживающих автоматизированное проектирование реляционных баз данных. Среди множества разновидностей ER-моделей одна из наиболее развитых применяется в системе CASE фирмы ORACLE. Ее мы и рассмотрим. Более точно, мы сосредоточимся на структурной части этой модели.
4.5.1.1. Основные понятия модели Entity-Relationship (Сущность-Связи)
Ниже изображена сущность АЭРОПОРТ с примерными объектами Шереметьево и Хитроу:
| АЭРОПОРТ например, Шереметьево, Хитроу |
Каждый экземпляр сущности должен быть отличим от любого другого экземпляра той же сущности (это требование в некотором роде аналогично требованию отсутствия кортежей-дубликатов в реляционных таблицах).
В изображенном ниже примере связь между сущностями БИЛЕТ и ПАССАЖИР связывает билеты и пассажиров. При том конец сущности с именем «для» позволяет связывать с одним пассажиром более одного билета, причем каждый билет должен быть связан с каким-либо пассажиром. Конец сущности с именем «имеет» означает, что каждый билет может принадлежать только одному пассажиру, причем пассажир не обязан иметь хотя бы один билет.
На следующем примере изображена рекурсивная связь, связывающая сущность ЧЕЛОВЕК с ней же самой. Конец связи с именем «сын» определяет тот факт, что у одного отца может быть более чем один сын. Конец связи с именем «отец» означает, что не у каждого человека могут быть сыновья.
Атрибутом сущности является любая деталь, которая служит для уточнения, идентификации, классификации, числовой характеристики или выражения состояния сущности. Имена атрибутов заносятся в прямоугольник, изображающий сущность, под именем сущности и изображаются малыми буквами, возможно, с примерами.
Пример:
| ЧЕЛОВЕК | |
| имя | |
возраст | пол | |
Уникальным идентификатором сущности является атрибут, комбинация атрибутов, комбинация связей или комбинация связей и атрибутов, уникально отличающая любой экземпляр сущности от других экземпляров сущности того же типа.
4.5.1.2. Нормальные формы ER-схем
Как и в реляционных схемах баз данных, в ER-схемах вводится понятие нормальных форм, причем их смысл очень близко соответствует смыслу реляционных нормальных форм. Заметим, что формулировки нормальных форм ER-схем делают более понятным смысл нормализации реляционных схем. Мы приведем только очень краткие и неформальные определения трех первых нормальных форм.
В первой нормальной форме ER-схемы устраняются повторяющиеся атрибуты или группы атрибутов, т.е. производится выявление неявных сущностей, «замаскированных» под атрибуты.
Во второй нормальной форме устраняются атрибуты, зависящие только от части уникального идентификатора. Эта часть уникального идентификатора определяет отдельную сущность.
В третьей нормальной форме устраняются атрибуты, зависящие от атрибутов, не входящих в уникальный идентификатор. Эти атрибуты являются основой отдельной сущности.
4.5.1.3. Более сложные элементы ER-модели
Эти и другие более сложные элементы модели данных «Сущность-Связи» делают ее существенно более мощной, но одновременно несколько усложняют ее использование. Конечно, при реальном использовании ER-диаграмм для проектирования баз данных необходимо ознакомиться со всеми возможностями.
Сущность может быть расщеплена на два или более взаимно исключающих подтипа, каждый из которых включает общие атрибуты и/или связи. Эти общие атрибуты и/или связи явно определяются один раз на более высоком уровне. В подтипах могут определяться собственные атрибуты и/или связи. В принципе подтипизация может продолжаться на более низких уровнях, но опыт показывает, что в большинстве случаев оказывается достаточно двух-трех уровней.
Сущность, на основе которой определяются подтипы, называется супертипом. Подтипы должны образовывать полное множество, т.е. любой экземпляр супертипа должен относиться к некоторому подтипу. Иногда для полноты приходится определять дополнительный подтип ПРОЧИЕ.
Пример: Супертип ЛЕТАТЕЛЬНЫЙ АППАРАТ
Как полагается это читать? От супертипа: ЛЕТАТЕЛЬНЫЙ АППАРАТ, который должен быть АЭРОПЛАНОМ, ВЕРТОЛЕТОМ, ПТИЦЕЛЕТОМ или ДРУГИМ ЛЕТАТЕЛЬНЫМ АППАРАТОМ. От подтипа: ВЕРТОЛЕТ, который относится к типу ЛЕТАТЕЛЬНОГО АППАРАТА. От подтипа, который является одновременно супертипа: АЭРОПЛАН, который относится к типу ЛЕТАТЕЛЬНОГО АППАРАТА и должен быть ПЛАНЕРОМ или МОТОРНЫМ САМОЛЕТОМ.
4.5.1.4. Получение реляционной схемы из ER-схемы
Шаг 3. Компоненты уникального идентификатора сущности превращаются в первичный ключ таблицы. Если имеется несколько возможных уникальных идентификатора, выбирается наиболее используемый. Если в состав уникального идентификатора входят связи, к числу столбцов первичного ключа добавляется копия уникального идентификатора сущности, находящейся на дальнем конце связи (этот процесс может продолжаться рекурсивно). Для именования этих столбцов используются имена концов связей и/или имена сущностей.
Шаг 5. Индексы создаются для первичного ключа (уникальный индекс), внешних ключей и тех атрибутов, на которых предполагается в основном базировать запросы.
При применении способа (а) таблица создается для наиболее внешнего супертипа, а для подтипов могут создаваться представления. В таблицу добавляется по крайней мере один столбец, содержащий код ТИПА; он становится частью первичного ключа.
Легкий доступ к супертипу и подтипам
Требуется меньше таблиц
Программы работают только с нужными таблицами
Требуется дополнительная логика работы с разными наборами столбцов и разными ограничениями
Потенциальное узкое место (в связи с блокировками)
Столбцы подтипов должны быть необязательными
В некоторых СУБД для хранения неопределенных значений требуется дополнительная память
Смущающие столбцы в представлении UNION
Потенциальная потеря производительности при работе через UNION
Над супертипом невозможны модификации
Если остающиеся внешние ключи все в одном домене, т.е. имеют общий формат (способ (а)), то создаются два столбца: идентификатор связи и идентификатор сущности. Столбец идентификатора связи используется для различения связей, покрываемых дугой исключения. Столбец идентификатора сущности используется для хранения значений уникального идентификатора сущности на дальнем конце соответствующей связи.
Альтернативные модели сущностей:
Вариант 2 (существенно лучше, если подтипы действительно существуют)
Вариант 3 (годится при наличии осмысленного супертипа D).
Конечно, способ представления ER-диаграмм, используемый компанией Oracle, не является единственным. В этом подразделе мы представляем несколько других нотаций.
4.5.2.1. Case-метод Баркера
Нотация ER-диаграммы была впервые введена П. Ченом (Chen) и получила дальнейшее развитие в работах Баркера. Метод Баркера будет излагаться на примере предметной области компании по торговле автомобилями. Ниже приведены выдержки из интервью, проведенного с персоналом компании.
Продавец: ему нужно знать, какую цену запрашивать и какова нижняя цена, за которую можно совершить сделку. Кроме того, ему нужна основная информация о машинах: год выпуска, марка, модель и т.п.
Администратор: его задача сводится к составлению контрактов, для чего нужна информация о покупателе, автомашине и продавце, поскольку именно контракты приносят продавцам вознаграждения за продажи.
Рис. 4.1. Графическое изображение сущности
Следующим шагом моделирования является идентификация связей.
Связи может даваться имя, выражаемое грамматическим оборотом глагола и помещаемое возле линии связи. Имя каждой связи между двумя данными сущностями должно быть уникальным, но имена связей в модели не обязаны быть уникальными. Имя связи всегда формируется с точки зрения родителя, так что предложение может быть образовано соединением имени сущности-родителя, имени связи, выражения степени и имени сущности-потомка.
Степень связи и обязательность графически изображаются следующим образом (рисунок 4.3).
Таким образом, 2 предложения, описывающие связь продавца с контрактом, графически будут выражены следующим образом (рисунок 4.4).
Описав также связи остальных сущностей, получим следующую схему (рисунок 4.5).
Последним шагом моделирования является идентификация атрибутов.
Каждый атрибут идентифицируется уникальным именем, выражаемым грамматическим оборотом существительного, описывающим представляемую атрибутом характеристику. Атрибуты изображаются в виде списка имен внутри блока ассоциированной сущности, причем каждый атрибут занимает отдельную строку. Атрибуты, определяющие первичный ключ, размещаются наверху списка и выделяются знаком «#».
С учетом имеющейся информации дополним построенную ранее диаграмму (рисунок 4.8).
Помимо перечисленных основных конструкций модель данных может содержать ряд дополнительных.
Подтипы и супертипы: одна сущность является обобщающим понятием для группы подобных сущностей (рисунок 4.9).
Взаимно исключающие связи: каждый экземпляр сущности участвует только в одной связи из группы взаимно исключающих связей (рисунок 4.10).
Рис. 4.9. Подтипы и супертипы
Рис. 4.10. Взаимно исключающие связи
Рекурсивная связь: сущность может быть связана сама с собой (рисунок 4.11).
Неперемещаемые (non-transferable) связи: экземпляр сущности не может быть перенесен из одного экземпляра связи в другой (рисунок 4.12).
Рис. 4.11. Рекурсивная связь
Рис. 4.12. Неперемещаемая связь
4.5.2.2. Методология IDEF1
Сущность в методологии IDEF1X является независимой от идентификаторов или просто независимой, если каждый экземпляр сущности может быть однозначно идентифицирован без определения его отношений с другими сущностями. Сущность называется зависимой от идентификаторов или просто зависимой, если однозначная идентификация экземпляра сущности зависит от его отношения к другой сущности (рисунок 4.13).
Каждой сущности присваивается уникальное имя и номер, разделяемые косой чертой «/» и помещаемые над блоком.
Рис.4.14. Мощность связи
Идентифицирующая связь между сущностью-родителем и сущностью-потомком изображается сплошной линией (рисунок 4.15). Сущность-потомок в идентифицирующей связи является зависимой от идентификатора сущностью. Сущность-родитель в идентифицирующей связи может быть как независимой, так и зависимой от идентификатора сущностью (это определяется ее связями с другими сущностями).
Рис. 4.15. Идентифицирующая связь
Пунктирная линия изображает неидентифицирующую связь (рисунок 4.16). Сущность-потомок в неидентифицирующей связи будет независимой от идентификатора, если она не является также сущностью-потомком в какой-либо идентифицирующей связи.
Рис. 4.16. Неидентифицирующая связь
Атрибуты изображаются в виде списка имен внутри блока сущности. Атрибуты, определяющие первичный ключ, размещаются наверху списка и отделяются от других атрибутов горизонтальной чертой (рисунок 4.17).
Рис. 4.17. Атрибуты и первичные ключи
Сущности могут иметь также внешние ключи (Foreign Key), которые могут использоваться в качестве части или целого первичного ключа или неключевого атрибута. Внешний ключ изображается с помощью помещения внутрь блока сущности имен атрибутов, после которых следуют буквы FK в скобках (рисунок 4.18).
Рис. 4.18. Примеры внешних ключей
4.5.2.3. Подход, используемый в CASE-средстве Vantage Team Builder
Рис. 4.19. Обозначение сущностей и связей
В необязательной связи (рисунок 4.20) могут участвовать не все экземпляры сущности.
Рис. 4.20. Необязательная связь
В отличие от необязательной связи в полной (total) связи участвуют все экземпляры хотя бы одной из сущностей. Это означает, что экземпляры такой связи существуют только при условии существования экземпляров другой сущ-ности. Полная связь может иметь один из 4-х видов: обязательная связь, слабая связь, связь «супертип-подтип» и ассоциативная связь.
Обязательная (mandatory) связь описывает связь между «независимой» и «зависимой» сущностями. Все экземпляры зависимой («обязательной») сущности могут существовать только при наличии экземпляров независимой («необязательной») сущности, т.е. экземпляр «обязательной» сущности может существовать только при условии существования определенного экземпляра «необязательной» сущности.
В примере (рисунок 4.21) подразумевается, что каждый автомобиль имеет по крайней мере одного водителя, но не каждый служащий управляет машиной.
Рис. 4.21. Обязательная связь
В слабой связи существование одной из сущностей, принадлежащей некоторому множеству («слабой») зависит от существования определенной сущности, принадлежащей другому множеству («сильной»), т.е. экземпляр «слабой» сущности может быть идентифицирован только посредством экземпляра «сильной» сущности. Ключ «сильной» сущности является частью составного ключа «слабой» сущности.
Слабая связь всегда является бинарной и подразумевает обязательную связь для «слабой» сущности. Сущность может быть «слабой» в одной связи и «сильной» в другой, но не может быть «слабой» более, чем в одной связи. Слабая связь может не иметь атрибутов.
Пример на рисунке 4.22: ключ (номер) строки в документе может не быть уникальным и должен быть дополнен ключом документа.
Рис.4.22. Слабая связь
Связь «супертип-подтип» изображена на рисунке 4.23. Общие характеристики (атрибуты) типа определяются в сущности-супер-типе, сущность-подтип наследует все характеристики супертипа. Экземпляр подтипа существует только при условии существования определенного экземпляра супертипа. Подтип не может иметь ключа (он импортирует ключ из супертипа). Сущность, являющаяся супертипом в одной связи, может быть подтипом в другой связи. Связь супертипа не может иметь атрибутов.
Рис. 4.23. Связь «супертип-подтип»
В примере на рисунке 4.24 самолет выполняет посадку на взлетную полосу в заданное время при оп-ределенной скорости и направлении ветра. Поскольку эти характеристики при-менимы только к конкретной посадке, они являются атрибутами посадки, а не самолета или взлетной полосы. Пилот, выполняющий посадку, связан гораздо сильнее с конкретной посадкой, чем с самолетом или взлетной полосой.
Рис. 4.24. Ассоциативная связь
Первичный ключ каждого типа сущности помечается звездочкой (*).
4.6. CASE-системы для проектирования информационных систем
Современные CASE-средства охватывают обширную область поддержки многочисленных технологий проектирования информационных систем: от простых средств анализа и документирования до полномасштабных средств автоматизации, покрывающих весь жизненный цикл программного обеспечения.
Наиболее трудоемкими этапами разработки информационных систем являются этапы анализа и проектирования, в процессе которых CASE-средства обеспечивают качество прини-маемых технических решений и подготовку проектной документации. При этом большую роль играют методы визуального представления информации. Это предполагает построение структурных или иных диа-грамм в реальном масштабе времени, использование многообразной цветовой палитры, сквозную проверку синтаксических правил. Графические средства моделирования предметной области позволяют разработчикам в наглядном виде изучать существующую информационную систему, перестраивать ее в соответствии с поставленными целями и имеющимися ограничениями.